MovieData
Project description: Personal python data analytics notebook from August 2025
Introduction
Do higher film budgets lead to more box office revenue? Let’s find out if there’s a relationship using IMDB 2023 Dataset from Kaggle.
Import Statements
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegressionNotebook Presentation
pd.options.display.float_format = '{:,.0f}'.format
pd.set_option('display.width', 400)
pd.set_option('display.max_columns', 10)Read the Data
df = pd.read_csv('imdb_data.csv')Explore and Clean the Data
#df.shape
#df.head()
#df.tail()
df.info()
df.sample(5)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3348 entries, 0 to 3347
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 3348 non-null object
1 primaryTitle 3348 non-null object
2 originalTitle 3348 non-null object
3 isAdult 3348 non-null int64
4 runtimeMinutes 3348 non-null int64
5 genres 3348 non-null object
6 averageRating 3348 non-null float64
7 numVotes 3348 non-null int64
8 budget 3348 non-null int64
9 gross 3297 non-null float64
10 release_date 3343 non-null object
11 directors 3348 non-null object
dtypes: float64(2), int64(4), object(6)
memory usage: 314.0+ KB| id | primaryTitle | originalTitle | isAdult | runtimeMinutes | … | numVotes | budget | gross | release_date | directors | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 833 | tt0134273 | 8MM | 8MM | 0 | 123 | … | 139984 | 40000000 | 96,618,699 | February 19, 1999 | Joel Schumacher |
| 1641 | tt0454841 | The Hills Have Eyes | The Hills Have Eyes | 0 | 107 | … | 180399 | 15000000 | 70,009,308 | March 10, 2006 | Alexandre Aja |
| 2620 | tt1821694 | RED 2 | RED 2 | 0 | 116 | … | 178197 | 84000000 | 148,075,565 | July 18, 2013 | Dean Parisot |
| 1161 | tt0294870 | Rent | Rent | 0 | 135 | … | 55315 | 40000000 | 31,670,620 | November 23, 2005 | Chris Columbus |
| 1332 | tt0362120 | Scary Movie 4 | Scary Movie 4 | 0 | 83 | … | 127234 | 45000000 | 178,262,620 | April 12, 2006 | David Zucker |
5 rows × 12 columns
Cleanup and conversions
- convert ‘September 18, 2019’ dates to datetime
- convert averageRating to numeric
- delete column isAdult as we wont need it
- drop empty gross
- fix singlevalue
df.drop(columns=['isAdult'], inplace=True) # not used
df.dropna(inplace=True) # 51 films have falsely 0 gross
df['release_date'] = pd.to_datetime(df['release_date'], format='mixed')
#df['averageRating'] = pd.to_numeric(df['averageRating'], errors='coerce').astype('float64')
df.loc[df.budget == 18, 'budget'] = 18000000 # fix single value
df['gross'] = pd.to_numeric(df['gross'], errors='coerce')
df.head(5)| id | primaryTitle | originalTitle | runtimeMinutes | genres | … | numVotes | budget | gross | release_date | directors | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | tt0035423 | Kate & Leopold | Kate & Leopold | 118 | Comedy,Fantasy,Romance | … | 87925 | 48000000 | 76,019,048 | 2001-12-11 | James Mangold |
| 1 | tt0065421 | The Aristocats | The AristoCats | 78 | Adventure,Animation,Comedy | … | 111758 | 4000000 | 35,459,543 | 1970-12-11 | Wolfgang Reitherman |
| 2 | tt0065938 | Kelly’s Heroes | Kelly’s Heroes | 144 | Adventure,Comedy,War | … | 52628 | 4000000 | 5,200,000 | 1970-01-01 | Brian G. Hutton |
| 3 | tt0066026 | M*A*S*H | M*A*S*H | 116 | Comedy,Drama,War | … | 75784 | 3500000 | 81,600,000 | 1970-01-25 | Robert Altman |
| 4 | tt0066206 | Patton | Patton | 172 | Biography,Drama,War | … | 106476 | 12000000 | 61,749,765 | 1970-02-04 | Franklin J. Schaffner |
5 rows × 11 columns
Descriptive Statistics
df.describe()| runtimeMinutes | averageRating | numVotes | budget | gross | release_date | |
|---|---|---|---|---|---|---|
| count | 3,292 | 3,292 | 3,292 | 3,292 | 3,292 | 3292 |
| mean | 113 | 7 | 217,090 | 50,468,636 | 168,264,559 | 2005-11-07 19:06:03.061968512 |
| min | 63 | 1 | 50,004 | 6,000 | 210 | 1970-01-01 00:00:00 |
| 25% | 98 | 6 | 79,396 | 15,000,000 | 36,283,303 | 1999-07-19 12:00:00 |
| 50% | 109 | 7 | 129,715 | 32,000,000 | 88,434,290 | 2007-09-29 00:00:00 |
| 75% | 124 | 7 | 249,003 | 68,000,000 | 200,995,146 | 2014-01-20 00:00:00 |
| max | 229 | 9 | 2,817,283 | 356,000,000 | 2,923,706,026 | 2023-10-25 00:00:00 |
| std | 20 | 1 | 249,472 | 51,786,917 | 236,752,803 | - |
- the average film costs about $50m to make and earns more than 3x (or $168m) in worldwide revenue.
- 25% are also profitable but only at around 2x budget rate.
- The lowest budget was $6,000 with the revenue of $126,052
- The highest production budget was $356,000,000 with highest worldwide revenue $2,923,706,026 or (8x the budget)!
I believe it should be Avatar by James Cameron, but lets check it out and also see the one with the lowest budget.
df[df.budget.isin([6000, 356000000])]| id | primaryTitle | originalTitle | runtimeMinutes | genres | … | numVotes | budget | gross | release_date | directors | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 878 | tt0154506 | Following | Following | 69 | Crime,Mystery,Thriller | … | 99219 | 6000 | 126,052 | 1998-04-24 | Christopher Nolan |
| 3055 | tt4154796 | Avengers: Endgame | Avengers: Endgame | 181 | Action,Adventure,Drama | … | 1224453 | 356000000 | 2,799,439,100 | 2019-04-18 | Anthony Russo, Joe Russo |
2 rows × 11 columns
Surprise, it’s now actually Avengers: Endgame! And the lowest budget is Following by Christopher Nolan, released in 1998… Never heard of it, but ok. Interesting is that it also made x21 the budget.
Films that Lost Money
Of course not all films are successfull, lets find out what is the percentage of films where the production costs exceeded the worldwide gross revenue?
money_losing = df.loc[df.budget > df.gross]
print(len(money_losing)/len(df))
0.14975698663426487
14.9% of films do not recoup their budget at the worldwide box office. Seems quite low but this dataset doesn’t include domestic revenue, so films that were never released worldwide are not even included.
Most common genres
genres = df['genres'].str.get_dummies(sep = ',')
plt.figure(figsize = (9,9))
plt.pie(genres.sum().sort_values(ascending = False),
labels = genres.sum().sort_values(ascending = False).index,
autopct='%1.1f%%',
colors = sns.color_palette("Paired"))
plt.title('Most common genres', fontweight = 'bold')
plt.tight_layout()
plt.show()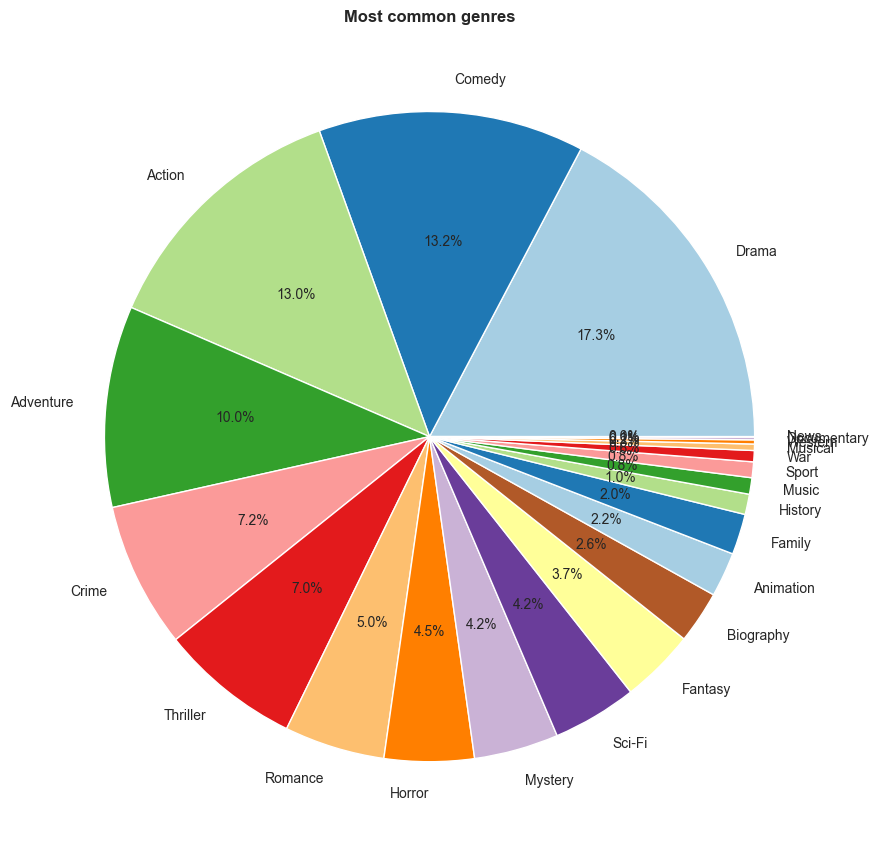
Genre with the most gross
df['genres'] = df['genres'].str.split(',')
df_exploded = df.explode('genres')
genre_gross = df_exploded.groupby('genres')['gross'].max().sort_values(ascending=False).head(10)
genre_names = genre_gross.index
max_gross = genre_gross.values
plt.figure(figsize=(12, 8))
sns.barplot(x=max_gross, y=genre_names, hue=max_gross, palette="viridis", legend=False, orient='h')
plt.ylabel('Genre')
plt.xlabel('Maximum Gross, $billions')
plt.title('Maximum Gross by Genre')
plt.show()genres Action 2,923,706,026 Fantasy 2,923,706,026 Adventure 2,923,706,026 Drama 2,799,439,100 Romance 2,264,743,305 Sci-Fi 2,071,310,218 Animation 1,663,075,401 Crime 1,515,341,399 Thriller 1,515,341,399 Comedy 1,453,683,476 Name: gross, dtype: float64
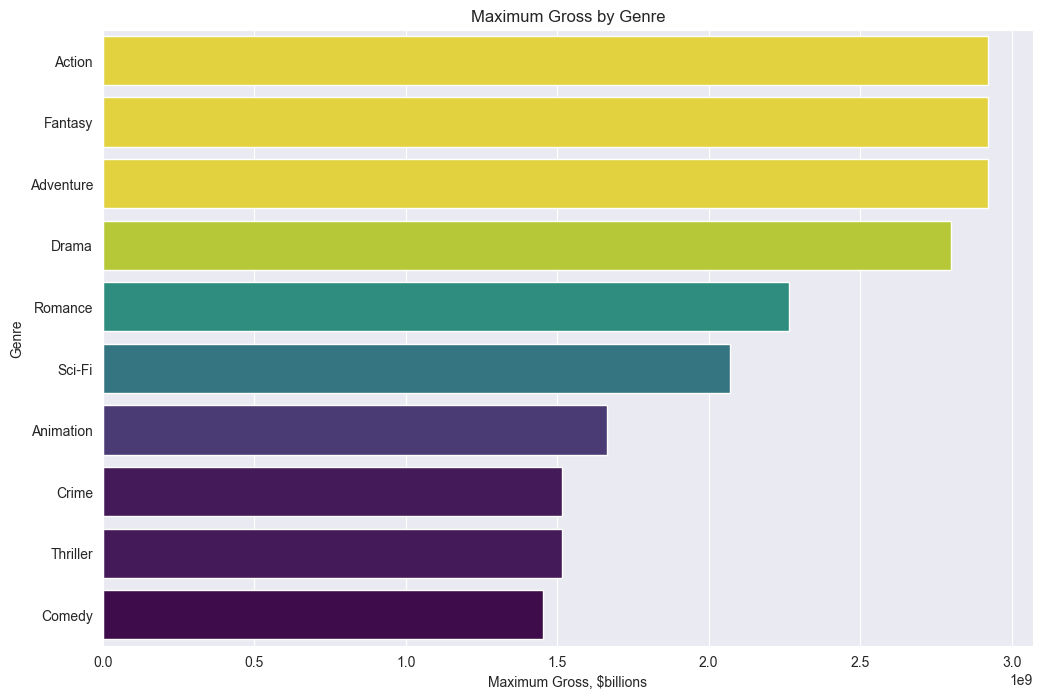
Most common genres: Adventure, Action, Drama also have max gross values. Interesting that Comedy gets replaced by Fantasy, which is only about 3.7%
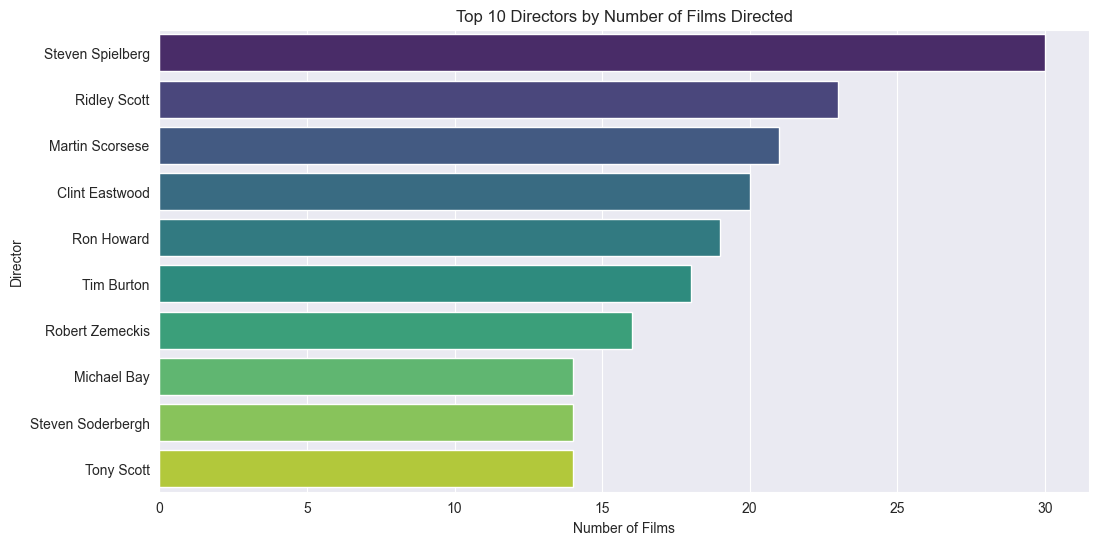
Directors with most films
top_directors = df["directors"].value_counts().head(10)
plt.figure(figsize=(12, 6))
sns.barplot(x=top_directors.values, y=top_directors.index, hue=top_directors.index, palette="viridis", legend=False, orient='h')
plt.title('Top 10 Directors by Number of Films Directed')
plt.xlabel('Number of Films')
plt.ylabel('Director')
plt.show()
Directors with max gross
dir_gross=df.groupby('directors')['gross'].max().sort_values(ascending=False).head(10)
director_names = dir_gross.index
max_gross = dir_gross.values
plt.figure(figsize=(10, 6))
sns.barplot(x=max_gross, y=director_names, hue=director_names, palette="viridis", legend=False, orient='h')
plt.ylabel('Directors')
plt.xlabel('Maximum Gross')
plt.title('Maximum Gross by Director (Top 10)')
plt.xticks(rotation=45, ha='right')
plt.show()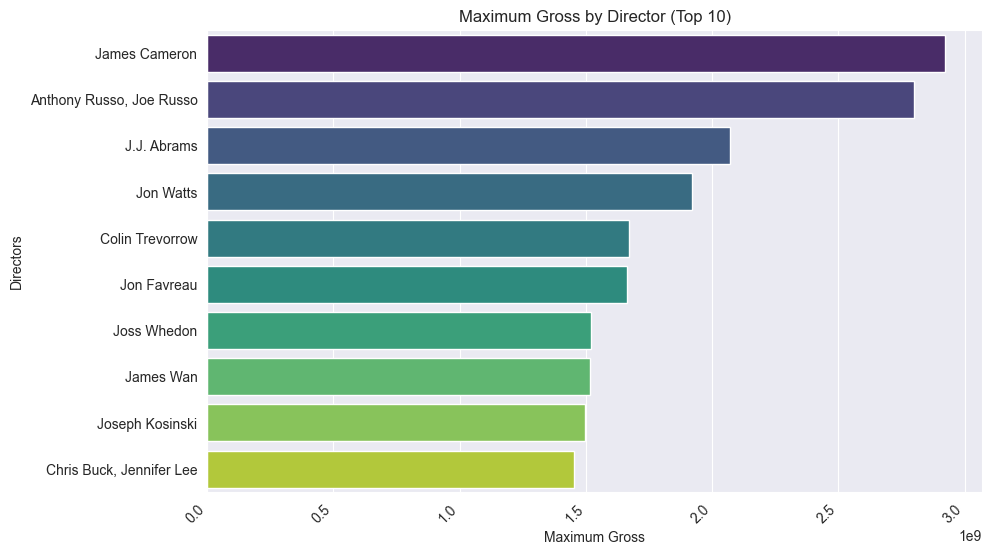
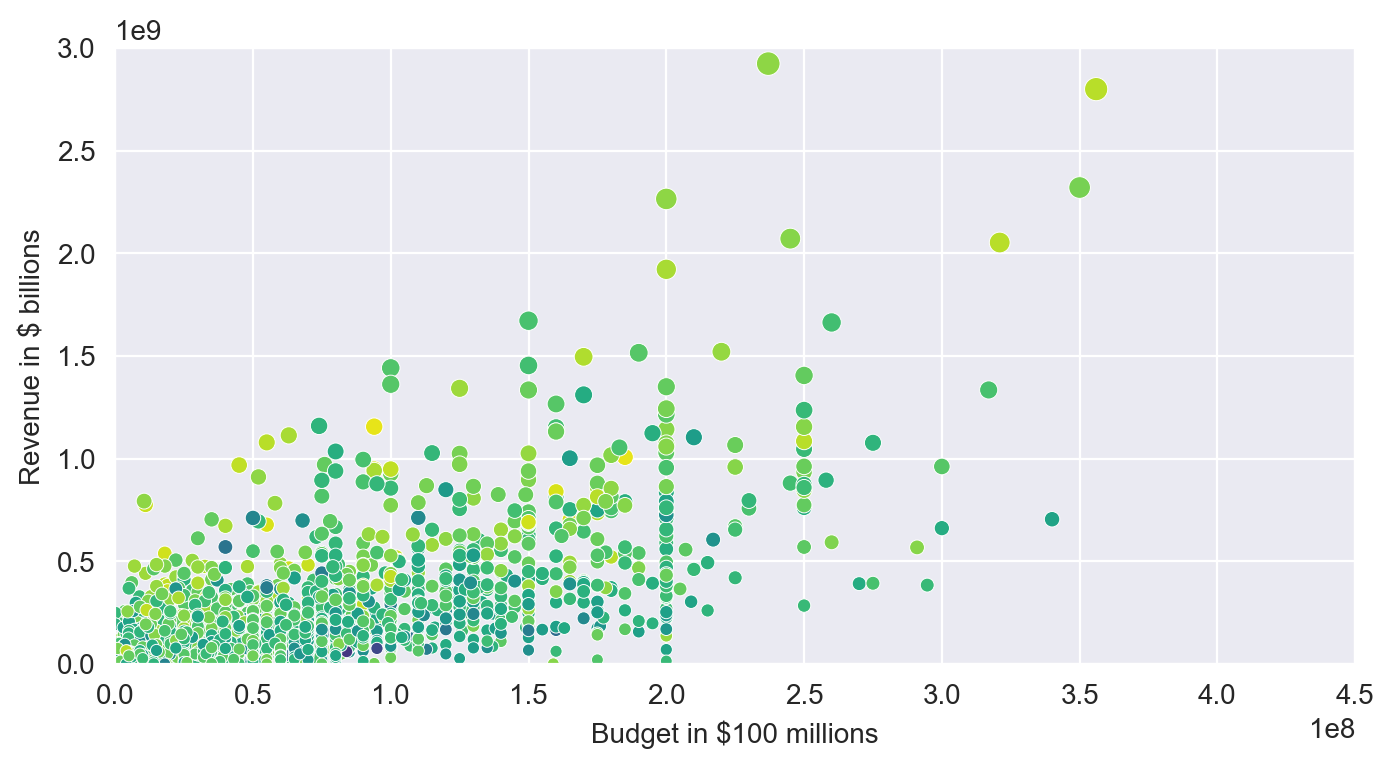
Budget vs Revenue (Seaborn Bubble Charts)
plt.figure(figsize=(8,4), dpi=200)
with sns.axes_style('darkgrid'):
ax = sns.scatterplot(data=df,
x='budget',
y='gross',
hue=('averageRating'),
palette="viridis",
legend=False,
size=('gross'))
ax.set(ylim=(0, 3000000000),
xlim=(0, 450000000),
ylabel='Revenue in $ billions',
xlabel='Budget in $100 millions')
plt.show()Bigger budget seems to correspond to higher revenue. And also budgets above $100m tend to stick to fix sums like 150, 200
Movie Releases over Time
plt.figure(figsize=(8,4), dpi=200)
with sns.axes_style('darkgrid'):
ax = sns.scatterplot(data=df,
x='release_date',
y='gross',
hue=('averageRating'),
legend=True,
palette="viridis",
size=('gross'))
ax.set(ylim=(0, 3000000000),
xlim=(df.release_date.min(), df.release_date.max()),
ylabel='Revenue in $ billions',
xlabel='Budget in $100 millions')
plt.show()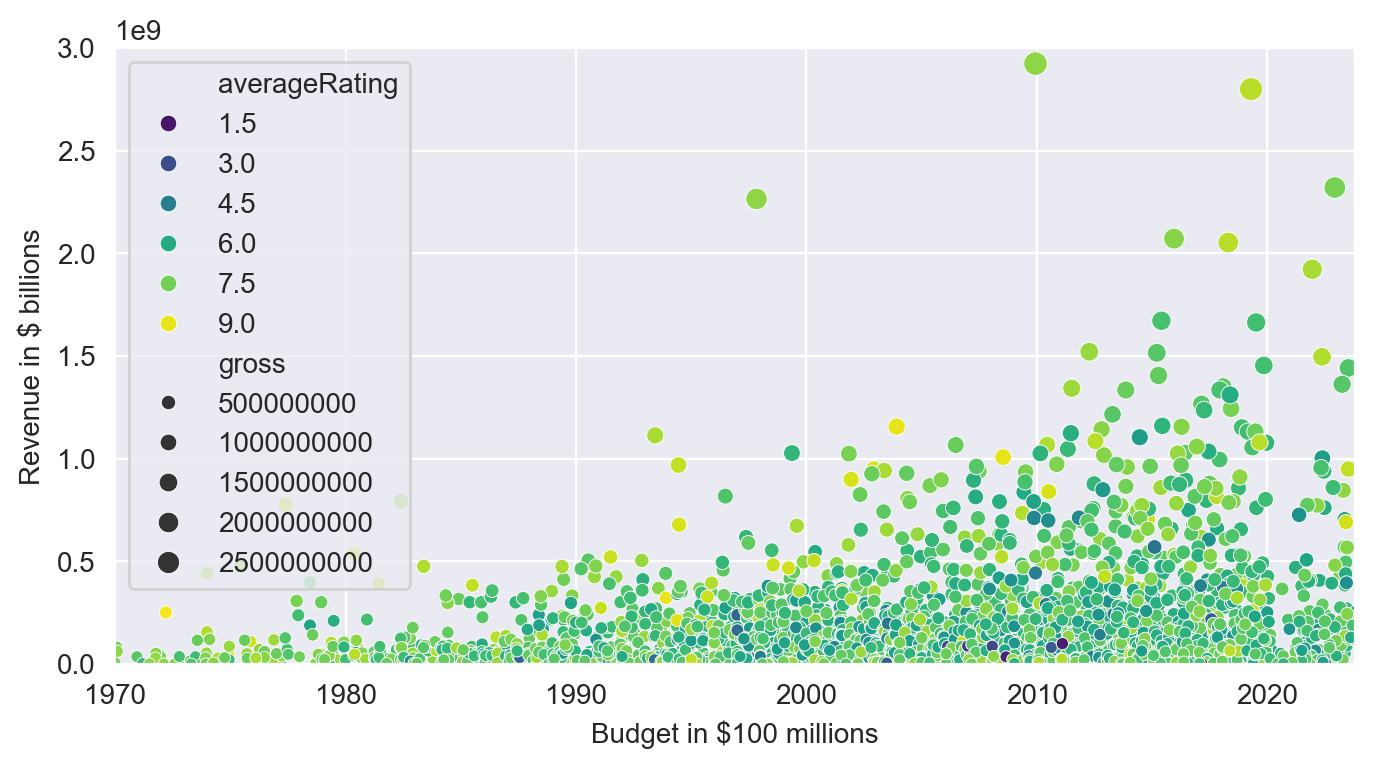
We clearly see a positive trend of budgets/revenue increasing over time
Seaborn Regression Plots
plt.figure(figsize=(8,4), dpi=200)
with sns.axes_style('darkgrid'):
ax = sns.regplot(data=df,
x='budget',
y='gross',
color='#2f4b7c',
scatter_kws = {'alpha': 0.3},
line_kws = {'color': '#ff7c43'})
ax.set(ylim=(0, 3000000000),
xlim=(0, 450000000),
ylabel='Revenue in $ billions',
xlabel='Budget in $100 millions')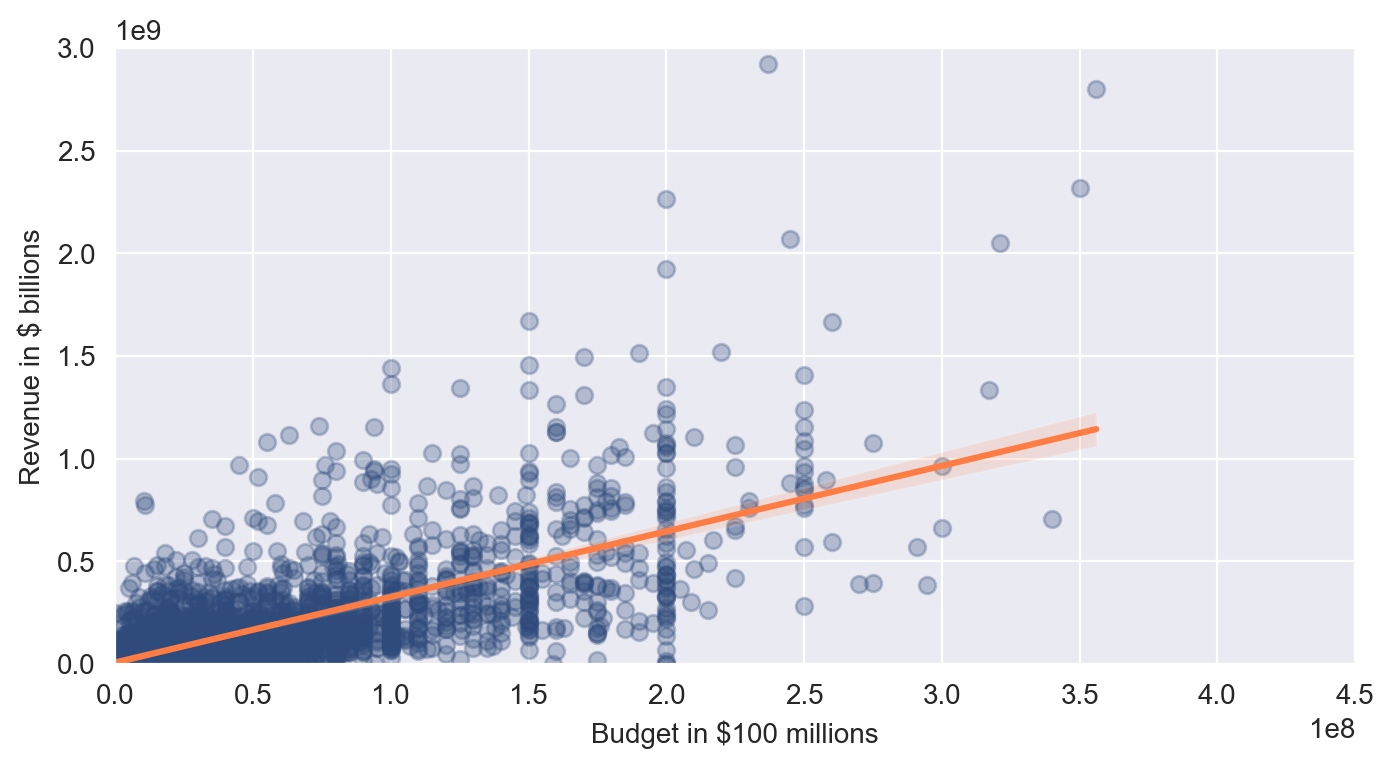
We also see that a film with a $150 million budget is predicted to make slightly under $500 million by our regression line. All in all, we can be pretty confident that there does indeed seem to be a relationship between a film’s budget and that film’s worldwide revenue.
Own Regression with scikit-learn
$ REVENUE = theta_0 + theta_1 * BUDGET $
regression = LinearRegression()
# Explanatory Variable or Feature
X = pd.DataFrame(df, columns=['budget'])
# Response Variable or Target
y = pd.DataFrame(df, columns=['gross'])
regression.fit(X, y)
# R-squared
regression.score(X, y)
theta0 = regression.intercept_[0] # y-intercept
theta1 = regression.coef_[0] # slope
r2 = regression.score(X,y) # r-squared
print(f"Y-Intercept (theta0) is {theta0}")
print(f"Slope coefficient(theta1) is {theta1}")
print(f"R-squared is {r2}")Y-Intercept (theta0) is 7157763.965588003 Slope coefficient(theta1) is [3.19221611] R-squared is 0.48756712843206695
- Y-intercept (theta0) tells us the estimated revenue for a given budget
- Slope (theta1) tells us that for every extra $1 in the budget, movie revenue increases by $3.19
- R-squared 0.48 means that our model explains about 48% of the variance in movie revenue. That’s actually pretty decent, considering we’ve got the simplest possible model, with only one explanatory variable.
Model Prediction
We just estimated the slope and intercept! Remember that our Linear Model has the following form:
$ REV \hat ENUE = \theta _0 + \theta _1 BUDGET$
budget = 350000000
revenue_estimate = theta0 + regression.coef_[0,0] * budget
revenue_estimate = round(revenue_estimate, -6)
print(f'The estimated revenue for a $350m film is around ${revenue_estimate:.10}.')The estimated revenue for a $350m film is around $1.124e+09.
So for a $350M we estimate $1.12B
That’s it, thanks for watching!